Comment les modèles d’intelligence artificielle transforment radicalement les résultats de recherche
La transformation numérique bouleverse la manière dont l’information circule sur le web. Si Google continue d’occuper une position dominante en tant que moteur de recherche traditionnel, l’émergence des modèles de langage génératifs redessine complètement le paysage de la retrouvailles d’information. Les systèmes tels que ChatGPT, Gemini et Perplexity proposent des réponses synthétiques qui s’éloignent des listes de liens bleus auxquelles les internautes sont habitués depuis des décennies. Cette mutation profonde de l’écosystème digital interroge la pertinence des stratégies de référencement naturel qui ont forgé le succès de millions de sites web.
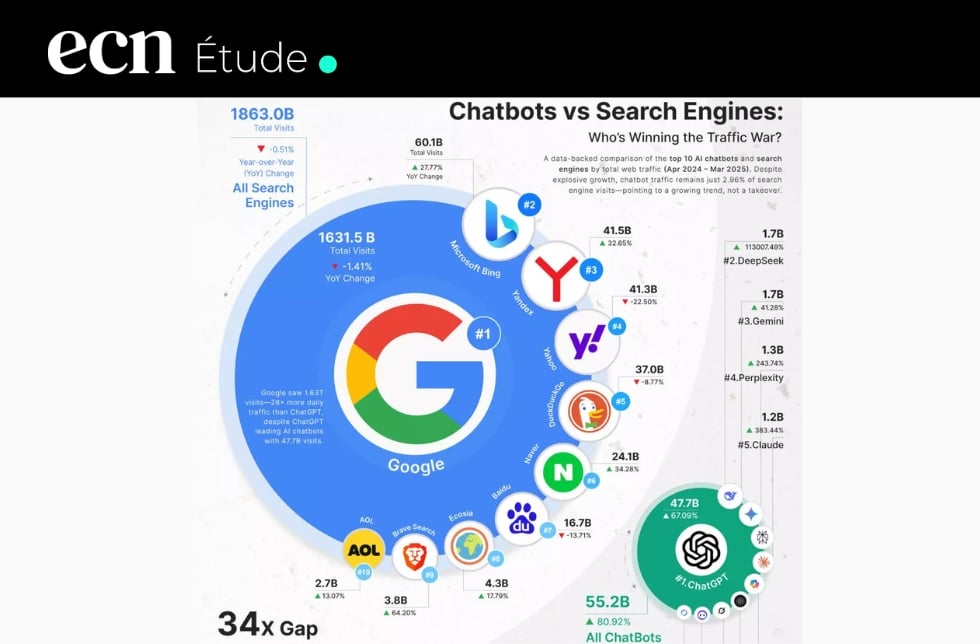
Une étude comparative menée par SearchAtlas sur plus de 18 000 requêtes identiques révèle l’ampleur de cette divergence. Les chercheurs ont scruté avec minutie les citations produites par trois modèles majeurs d’intelligence artificielle face aux résultats organiques de Google. L’objectif consistait à mesurer le taux de recouvrement entre les sources présentées par le géant de Mountain View et celles sélectionnées par les algorithmes génératifs. Les écarts observés dépassent largement les anticipations des professionnels du SEO, révélant une réalité complexe où les règles établies depuis vingt ans ne s’appliquent plus systématiquement.
Les moteurs de recherche classiques reposent sur une indexation exhaustive des pages web, associée à des critères de pertinence basés sur les liens entrants, la fraîcheur du contenu, les signaux d’engagement utilisateur et des centaines d’autres facteurs. Les systèmes d’IA générative adoptent une approche fondamentalement différente : ils s’appuient sur leur entraînement préalable, complété parfois par une recherche en temps réel, pour générer des réponses cohérentes. Cette mécanique alternative modifie radicalement les paramètres de la visibilité en ligne, obligeant les éditeurs à repenser leurs stratégies de production de contenu. Un phénomène similaire à celui observé dans l’évolution des infrastructures matérielles dédiées à l’IA, qui redéfinissent les capacités de traitement et de génération.

Les mécanismes distincts de sélection des sources par les algorithmes intelligents
Perplexity se distingue comme le seul modèle du trio analysé à intégrer une recherche innovante en direct dans son processus de génération. Cette fonctionnalité rapproche son comportement de celui d’un moteur traditionnel, avec un recouvrement de 25 à 30% au niveau des domaines apparaissant dans Google. La correspondance monte à environ 20% pour les URLs spécifiques, un chiffre significatif qui témoigne d’une continuité partielle entre les pratiques SEO établies et les résultats fournis par ce système. Au total, Perplexity partage près de 18 500 domaines avec Google, représentant plus de 40% de l’ensemble de ses sources citées.
ChatGPT adopte une stratégie radicalement différente en fonctionnant sans recherche web instantanée par défaut. Le modèle privilégie une logique de synthèse basée sur ses connaissances internes, consolidées lors de sa phase d’entraînement. Cette approche réduit drastiquement le recouvrement avec les résultats de Google : seulement 10 à 15% pour les domaines, et moins de 10% pour les URLs précises. Les sites web optimisés pour le référencement naturel ne bénéficient donc pas automatiquement d’une visibilité auprès de ce système, même s’ils dominent les pages de résultats traditionnels. Cette divergence soulève des questions fondamentales sur la nature même de la pertinence en ligne.
Gemini, pourtant développé par Google, surprend par une faible proximité avec les résultats du moteur maison. Les citations produites par ce modèle varient considérablement d’une requête à l’autre, suggérant une logique de sélection imprévisible pour les éditeurs. L’étude révèle un partage de seulement 160 domaines avec Google sur l’ensemble des requêtes analysées, soit approximativement 4% des domaines du moteur. Paradoxalement, ces mêmes domaines constituent 28% des sources de Gemini, indiquant une concentration sur une base restreinte de sites privilégiés. Cette sélectivité filtrée s’éloigne des pratiques SEO actuelles et laisse présager une mutation profonde des critères de visibilité.
| Modèle IA | Recouvrement domaines avec Google | Recouvrement URLs avec Google | Recherche web en temps réel |
|---|---|---|---|
| Perplexity | 25-30% | ~20% | Oui |
| ChatGPT | 10-15% | <10% | Non (par défaut) |
| Gemini | ~4% | Variable | Variable |
Les implications concrètes pour les stratégies de visibilité numérique
La divergence entre les résultats de Google et ceux des modèles génératifs remet en question les fondamentaux du référencement naturel. Apparaître en première page du moteur californien ne garantit plus d’être cité par une technologie IA dans ses réponses synthétiques. Pour les sites disposant d’une stratégie SEO bien rodée, Perplexity représente une continuité relative, permettant de capitaliser partiellement sur les efforts d’optimisation déjà consentis. En revanche, ChatGPT et Gemini suivent leur propre logique, déconnectée des signaux de classement traditionnels, obligeant les créateurs de contenu à réinventer leur approche de la production éditoriale.
Cette situation engendre une fragmentation de l’écosystème digital. Les professionnels du marketing de contenu doivent désormais concevoir leurs publications en pensant simultanément à plusieurs publics : les robots d’indexation de Google, les modèles de langage pré-entraînés, et les systèmes hybrides combinant les deux approches. Cette complexification multiplie les contraintes créatives et techniques, tout en réduisant la prévisibilité des résultats. Les investissements en SEO ne deviennent pas obsolètes pour autant, mais leur rendement devient plus incertain face à l’ascension des réponses alternatives générées par l’IA.
Les sites d’actualité, de documentation technique et de commerce électronique se trouvent particulièrement exposés à cette transformation. Un article de journal optimisé pour Google, bénéficiant d’une autorité de domaine élevée et de backlinks de qualité, peut parfaitement passer sous le radar d’un modèle génératif qui privilégiera des sources consolidées dans sa mémoire interne. À l’inverse, un site peu visible sur Google pourrait être régulièrement cité par ChatGPT si son contenu figurait dans les corpus d’entraînement du modèle. Cette asymétrie redistribue les cartes de la visibilité en ligne, favorisant potentiellement de nouveaux acteurs tout en marginalisant d’autres, dans une logique parfois difficile à anticiper. Un phénomène comparable à l’effet disruptif de l’IA sur les modèles d’affaires établis.
Les critères de sélection des sources dans les modèles de langage génératifs
Les algorithmes intelligents qui sous-tendent les modèles génératifs ne fonctionnent pas comme les robots d’indexation traditionnels. Leur sélection de sources repose sur plusieurs mécanismes entrelacés : la fréquence d’apparition d’un domaine dans les données d’entraînement, la qualité perçue des contenus lors de la phase d’apprentissage, et parfois des filtres éditoriaux appliqués en amont par les équipes de développement. Un site peut ainsi être privilégié non pas pour son autorité SEO actuelle, mais pour sa présence historique dans les archives du web ayant servi à entraîner le modèle il y a plusieurs mois ou années.
Cette mécanique temporelle introduit un décalage entre la réalité contemporaine du web et les connaissances figées des IA. Un nouveau média lancé récemment, même s’il produit du contenu de haute qualité et grimpe rapidement dans les résultats Google, restera invisible pour ChatGPT jusqu’à ce que le modèle soit réentraîné ou actualisé. Perplexity contourne partiellement ce problème grâce à sa recherche en temps réel, mais les deux autres systèmes étudiés maintiennent un fossé temporel qui désavantage structurellement les acteurs récents. Cette inertie bouleverse la dynamique traditionnelle du web, où la fraîcheur du contenu constituait un atout majeur.
Les implications juridiques et éthiques de ces choix de sources méritent également une attention soutenue. Lorsqu’un modèle d’IA cite systématiquement un nombre restreint de domaines, il concentre le trafic et l’influence sur quelques acteurs privilégiés, potentiellement au détriment de la diversité informationnelle. Les éditeurs exclus de cette sélection restreinte perdent non seulement du trafic direct, mais aussi de la notoriété et des opportunités de monétisation. Cette concentration soulève des interrogations sur la régulation nécessaire pour maintenir un écosystème équilibré, permettant aux nouveaux entrants de concurrencer les acteurs établis.
- Fréquence d’apparition dans les corpus d’entraînement : les sites massivement indexés historiquement bénéficient d’un avantage durable
- Qualité éditoriale perçue : les contenus bien structurés et factuels sont favorisés dans les mémoires des modèles
- Filtres éditoriaux appliqués : certaines catégories de sites peuvent être exclues pour des raisons de modération
- Décalage temporel des connaissances : les nouveaux acteurs restent invisibles jusqu’aux mises à jour du modèle
- Dépendance aux métadonnées : la structuration des données influence la facilité de citation par les IA

La reconfiguration des comportements de recherche des utilisateurs
Les internautes modifient progressivement leur manière d’interroger le web. Face à une question complexe nécessitant une synthèse d’informations provenant de multiples sources, de plus en plus d’utilisateurs se tournent vers ChatGPT ou Gemini plutôt que de parcourir une liste de liens Google. Cette évolution comportementale témoigne d’une préférence croissante pour les réponses alternatives fournies directement, sans nécessiter de navigation supplémentaire. Le modèle traditionnel du clic vers un site tiers s’efface au profit d’une interaction conversationnelle où l’IA agrège et reformule l’information pour l’utilisateur.
Cette transformation impacte directement le modèle économique du web. Les sites éditoriaux financés par la publicité dépendent du trafic entrant pour générer des revenus. Si les réponses d’IA suffisent aux utilisateurs sans nécessiter de visite sur la source originale, le trafic s’effondre, menaçant la viabilité économique de nombreux médias. Google lui-même expérimente des fonctionnalités de synthèse par IA intégrées aux résultats de recherche, accélérant cette tendance à retenir l’utilisateur dans son propre écosystème. Le web ouvert, basé sur l’échange de liens et de visites, se trouve ainsi confronté à un modèle concurrentiel où l’information est consommée sans déplacement, comme illustré par les avancées technologiques de Google dans l’intégration de l’IA à ses services.
Les comportements de recherche varient également selon les types de requêtes. Pour des informations factuelles simples, les IA génératives excellent en fournissant une réponse directe et fiable. Pour des recherches transactionnelles, comme l’achat d’un produit, Google maintient son avantage grâce à ses résultats sponsorisés et ses fiches produits structurées. Les requêtes nécessitant une expertise approfondie ou une diversité de points de vue restent mieux servies par une navigation multi-sources traditionnelle. Cette segmentation crée une coexistence complexe entre les différents modes de recherche, où chacun conserve une pertinence selon le contexte.
L’adaptation nécessaire des producteurs de contenu face aux transformations numériques
Les créateurs de contenu doivent repenser leur stratégie éditoriale pour maximiser leur visibilité dans cet environnement fragmenté. Produire des articles optimisés pour le SEO traditionnel ne suffit plus : il devient crucial de structurer l’information de manière à faciliter son extraction et sa reformulation par les modèles d’IA. Cela passe par l’utilisation intensive de données structurées, de balises sémantiques claires, et d’une architecture informationnelle logique. Les contenus doivent être conçus pour être à la fois lisibles par les humains et facilement parsing par les algorithmes génératifs.
La diversification des canaux de publication s’impose également. Plutôt que de miser uniquement sur le trafic organique depuis Google, les éditeurs explorent des partenariats directs avec les plateformes d’IA, négociant l’intégration de leurs contenus dans les sources privilégiées des modèles. OpenAI, Anthropic et Google concluent des accords avec des médias pour accéder légalement à leurs archives, offrant en contrepartie une visibilité accrue dans les réponses générées. Ces négociations redessinent les rapports de force entre producteurs et distributeurs d’information, introduisant une dimension contractuelle absente du SEO traditionnel.
La qualité du contenu devient un facteur différenciant encore plus critique. Les modèles d’IA tendent à privilégier les sources réputées pour leur fiabilité factuelle et leur neutralité. Investir dans le journalisme d’investigation, la production de données originales, et l’expertise vérifiable devient une stratégie payante pour figurer parmi les sources citées. À l’inverse, les contenus superficiels, dupliqués ou générés automatiquement risquent d’être ignorés tant par les algorithmes de Google que par les modèles génératifs. Cette convergence vers l’exigence qualitative pourrait paradoxalement améliorer la santé informationnelle du web, en marginalisant les fermes de contenu de faible valeur.
| Stratégie d’adaptation | Objectif | Bénéfice attendu |
|---|---|---|
| Structuration sémantique renforcée | Faciliter l’extraction par les IA | Augmentation des citations par les modèles |
| Partenariats avec plateformes IA | Intégration contractuelle des contenus | Visibilité garantie dans les réponses |
| Production de données originales | Se positionner comme source primaire | Autorité accrue et citations fréquentes |
| Diversification des formats | Atteindre différents publics | Résilience face aux changements algorithmiques |
Le futur de la recherche entre intelligence artificielle et moteurs traditionnels
L’avenir de la recherche d’information se dessine comme une cohabitation entre plusieurs paradigmes. Google n’abandonnera pas son modèle de liens sponsorisés, trop lucratif pour être écarté, mais intégrera progressivement des couches d’IA générative pour enrichir l’expérience utilisateur. Les modèles conversationnels continueront de gagner en sophistication, proposant des réponses de plus en plus contextuelles et personnalisées. Cette convergence pourrait aboutir à des interfaces hybrides, combinant synthèse par IA et accès direct aux sources pour les utilisateurs souhaitant approfondir. Le futur de la recherche se caractérisera probablement par cette multiplicité des points d’entrée, selon les besoins spécifiques de chaque requête.
Les régulateurs scrutent attentivement ces évolutions, conscients des enjeux de concentration et de pluralisme. L’Union européenne notamment envisage d’appliquer les règles de concurrence aux plateformes d’IA dominantes, pour éviter la reproduction des monopoles observés avec les moteurs de recherche traditionnels. Des obligations de transparence sur les sources utilisées, de rémunération des éditeurs cités, et de diversité dans les réponses fournies pourraient être imposées. Ces contraintes réglementaires influenceront fortement l’architecture des systèmes d’IA et les modèles économiques associés, particulièrement dans un contexte où les investissements massifs dans les infrastructures témoignent des ambitions des géants technologiques.
Les utilisateurs eux-mêmes développeront une littératie accrue face à ces outils. Comprendre qu’une réponse d’IA résulte d’un processus statistique de génération, et non d’une recherche exhaustive, deviendra essentiel pour évaluer la fiabilité de l’information reçue. L’éducation aux médias et à l’information devra intégrer ces nouvelles formes de médiation algorithmique, enseignant à vérifier les sources, croiser les réponses de plusieurs systèmes, et identifier les biais potentiels. Cette montée en compétence collective conditionne la capacité des sociétés à tirer profit de ces technologies sans tomber dans la désinformation ou la dépendance intellectuelle.
Les enjeux de souveraineté numérique dans l’écosystème de la recherche augmentée par l’IA
La domination américaine sur les technologies de recherche, qu’elles soient traditionnelles ou basées sur l’IA, soulève des préoccupations stratégiques pour de nombreux pays. Google, Microsoft avec Bing et ChatGPT, ainsi que les modèles d’OpenAI, concentrent une part écrasante du marché mondial. Cette concentration confère aux États-Unis un contrôle de facto sur l’accès à l’information pour des milliards d’individus. Les initiatives européennes comme Mistral AI ou les projets asiatiques tentent de proposer des alternatives souveraines, mais peinent à rivaliser en termes de puissance de calcul et de qualité des résultats, notamment face à des acteurs comme ceux qui accèdent à des infrastructures de calcul massives.
Les données d’entraînement constituent un autre enjeu de souveraineté. Les modèles d’IA apprennent principalement à partir de contenus anglophones, reflétant les biais culturels et géopolitiques associés. Les langues minoritaires, les perspectives non-occidentales, et les connaissances locales se trouvent sous-représentées dans les réponses générées. Développer des modèles entraînés sur des corpus linguistiques et culturels diversifiés devient un impératif pour préserver la pluralité informationnelle. Plusieurs gouvernements investissent dans la création de datasets nationaux et le développement de modèles locaux, conscients que la dépendance technologique équivaut à une dépendance informationnelle.
Les infrastructures matérielles nécessaires pour faire tourner ces modèles représentent également un facteur de souveraineté. La production de puces spécialisées pour l’IA, dominée par NVIDIA et quelques fabricants asiatiques, crée des goulots d’étranglement stratégiques. Les investissements dans la fabrication européenne de semi-conducteurs, bien qu’ambitieux, accusent un retard considérable. Cette dépendance technologique limite la capacité des acteurs non-américains à développer des alternatives crédibles aux systèmes dominants, perpétuant un déséquilibre structurel dans le contrôle des technologies de recherche.
- Concentration géographique des acteurs majeurs : États-Unis et Chine dominent largement le marché
- Biais linguistiques et culturels : surreprésentation des contenus anglophones dans les entraînements
- Dépendance aux infrastructures étrangères : puces et datacenters concentrés dans quelques pays
- Initiatives souveraines en développement : projets européens, africains et sud-américains émergent progressivement
- Enjeux réglementaires divergents : approches différenciées entre régions sur la gouvernance de l’IA
Les bouleversements économiques induits par la mutation des canaux de recherche
L’économie digitale repose largement sur le trafic généré par les moteurs de recherche. Les sites e-commerce, les médias en ligne, les plateformes de services dépendent des clics entrants pour convertir des visiteurs en clients ou lecteurs. Si les réponses d’IA se suffisent à elles-mêmes, court-circuitant la visite sur le site source, c’est tout un modèle économique qui vacille. Les investissements publicitaires, évalués à plusieurs centaines de milliards de dollars annuellement dans le référencement payant et l’affichage display, pourraient se réorienter vers de nouveaux canaux encore à définir. Cette redistribution des budgets marketing provoquera des gagnants et des perdants dans l’écosystème digital.
Les plateformes d’IA elles-mêmes explorent différents modèles de monétisation. OpenAI propose des abonnements premium pour ChatGPT, Perplexity teste des formules sans publicité, tandis que Google intègre l’IA dans son moteur existant sans modifier fondamentalement son modèle publicitaire. La question de la rémunération des sources citées reste largement non résolue : les éditeurs revendiquent une compensation pour l’utilisation de leurs contenus, mais les cadres juridiques peinent à suivre le rythme de l’innovation technologique. Les négociations en cours entre plateformes d’IA et groupes médiatiques préfigurent les équilibres économiques futurs, avec des enjeux financiers considérables. Cette situation rappelle les débats autour de l’utilisation des données et la propriété intellectuelle dans d’autres secteurs technologiques.
Les petites entreprises et créateurs indépendants se trouvent particulièrement vulnérables face à cette transition. Contrairement aux grands groupes médiatiques capables de négocier des accords avec les géants de l’IA, les acteurs de niche ne disposent ni du poids ni des ressources pour faire valoir leurs droits. Le risque d’une concentration accrue de la visibilité et des revenus sur quelques acteurs dominants menace la diversité et la créativité qui ont fait la richesse du web participatif. Des mécanismes de redistribution équitable, inspirés des droits voisins appliqués à la presse, devront être inventés pour préserver un écosystème viable pour tous les contributeurs.
| Acteur économique | Impact de l’IA sur la recherche | Stratégie d’adaptation |
|---|---|---|
| Sites e-commerce | Baisse du trafic organique | Investissement dans les marketplaces et publicité IA |
| Médias en ligne | Perte de revenus publicitaires | Négociation d’accords de licence avec plateformes IA |
| Créateurs indépendants | Invisibilité croissante | Diversification vers newsletters et communautés directes |
| Plateformes IA | Opportunité de monétisation | Développement d’abonnements et de services B2B |
| Agences SEO | Évolution des prestations | Pivot vers l’optimisation pour IA et conseil stratégique |
L’évolution des compétences professionnelles dans le secteur du marketing digital
Les métiers du référencement naturel connaissent une mutation profonde. Les spécialistes SEO doivent désormais maîtriser non seulement les critères de classement de Google, mais aussi les mécanismes de sélection des sources par les modèles génératifs. Cette double compétence exige une compréhension fine de l’apprentissage automatique, des architectures de transformers, et des techniques de prompt engineering. Les formations professionnelles s’adaptent progressivement, intégrant des modules sur l’optimisation pour l’IA générative, mais le fossé reste important entre les compétences acquises et les besoins émergents.
La rédaction de contenu évolue également vers une approche plus structurée et data-driven. Les rédacteurs doivent penser en termes de granularité informationnelle, décomposant leurs articles en unités atomiques facilement extractibles par les algorithmes. L’usage de schémas de données structurées, de métadonnées enrichies, et de formats standardisés devient incontournable. Cette technicisation de l’écriture web peut sembler contraignante, mais elle ouvre aussi des opportunités créatives pour ceux qui maîtrisent l’articulation entre expression naturelle et optimisation algorithmique.
Les analystes de données jouent un rôle croissant dans l’évaluation de la performance des contenus face aux IA. Mesurer la fréquence de citation par différents modèles, identifier les facteurs favorisant la sélection, et ajuster les stratégies éditoriales en conséquence nécessite des compétences avancées en data science. Les outils d’analyse se développent pour tracer la présence d’un site dans les réponses génératives, créant un nouveau marché de services spécialisés. Cette professionnalisation du suivi de visibilité IA transforme les départements marketing, qui doivent recruter de nouveaux profils ou former leurs équipes existantes.

Pourquoi les résultats de ChatGPT diffèrent-ils autant de ceux de Google ?
ChatGPT fonctionne sans recherche web en temps réel par défaut et s’appuie sur ses connaissances internes consolidées lors de son entraînement. Il privilégie une logique de synthèse plutôt que de récupération dynamique, ce qui explique un recouvrement de seulement 10 à 15% avec les domaines présents dans Google. Les sites optimisés pour le SEO ne bénéficient donc pas automatiquement d’une visibilité dans ses réponses.
Comment optimiser son contenu pour être cité par les modèles d’IA générative ?
L’optimisation pour les IA passe par une structuration sémantique renforcée avec des données structurées, des balises claires et une architecture informationnelle logique. Il est également crucial de produire du contenu original, factuel et de haute qualité, tout en envisageant des partenariats directs avec les plateformes d’IA pour une intégration contractuelle de vos contenus dans leurs sources privilégiées.
Le SEO traditionnel est-il devenu obsolète avec l’arrivée des IA génératives ?
Le SEO traditionnel n’est pas obsolète mais doit évoluer. Google reste le principal moteur de recherche pour de nombreuses requêtes, particulièrement transactionnelles. Cependant, une stratégie de visibilité complète doit désormais prendre en compte les différentes logiques de sélection des sources par les modèles d’IA, en complément des pratiques SEO établies. Perplexity notamment maintient une continuité avec le référencement classique grâce à sa recherche en temps réel.
Quels sont les risques économiques pour les éditeurs de contenu face aux IA génératives ?
Les éditeurs font face à une baisse potentielle du trafic entrant si les utilisateurs se contentent des réponses synthétiques des IA sans visiter les sites sources. Cela menace directement les revenus publicitaires et les modèles économiques basés sur le trafic. Les petits acteurs sont particulièrement vulnérables, ne disposant pas du poids pour négocier des accords de licence avec les plateformes d’IA comme le font les grands groupes médiatiques.
Pourquoi Gemini cite-t-il si peu de sources présentes dans Google malgré leur origine commune ?
Gemini, bien que développé par Google, suit une logique de sélection très différente du moteur de recherche. L’étude révèle qu’il privilégie une base restreinte de sources, avec seulement 4% des domaines de Google partagés, mais ces domaines constituent 28% de ses citations. Cette concentration suggère des filtres éditoriaux spécifiques et une stratégie de curation distincte des critères de classement SEO traditionnels.