Les AI Overviews bouleversent les flux de visiteurs vers les sites d’information
Depuis que Google a généralisé l’affichage des résumés IA dans ses pages de résultats, l’équilibre entre le moteur de recherche en ligne et les producteurs de contenus a basculé. Ces aperçus, placés en position zéro, distillent une synthèse automatique d’informations issues de diverses sources, dispensant souvent l’internaute de cliquer sur les liens traditionnels. Cette nouvelle donne suscite des préoccupations majeures chez les éditeurs, qui voient leur trafic organique s’effriter mois après mois.
Au Royaume-Uni, l’Autorité de la concurrence et des marchés (CMA) prend désormais la mesure de ce phénomène. Sarah Cardell, sa directrice générale, a réclamé officiellement à Google l’intégration d’un dispositif permettant aux sites web d’exclure leurs contenus des AI Overviews, mais aussi de l’entraînement des modèles d’intelligence artificielle. L’objectif affiché est clair : offrir un contrôle plus fin aux acteurs économiques, notamment ceux du secteur de la presse, et garantir un traitement plus équitable dans l’exploitation de leurs créations numériques.
Cette intervention réglementaire intervient dans un contexte de tensions croissantes. De nombreux groupes de médias rapportent une baisse sensible de leur trafic web depuis l’apparition de ces résumés automatisés. Pour certains observateurs, l’impact numérique ne se limite pas à une simple question de visibilité, mais renvoie à une captation de valeur au détriment des producteurs originaux. Tim Cowen, cofondateur du Movement for an Open Web, estime que permettre un simple retrait des AI Overviews ne compensera pas les pertes déjà enregistrées et appelle à des mesures structurelles plus contraignantes, voire à des compensations financières.
Du côté de Mountain View, on assure « explorer » des solutions pour améliorer la granularité des contrôles offerts aux éditeurs. Les paramètres existants, tels que Google-Extended ou les balises « nosnippet », demeurent imparfaits. Le premier bloque l’entraînement des modèles mais pas l’affichage dans les résumés, tandis que les seconds affectent également l’affichage dans les résultats classiques, pénalisant la visibilité globale d’un site. Aucune feuille de route ni calendrier précis n’a été communiqué, témoignant de la complexité à concilier innovation, expérience utilisateur et respect des intérêts économiques des créateurs de contenus.

Comment la technologie IA redéfinit les règles du SEO
L’irruption des algorithmes génératifs dans les moteurs de recherche modifie en profondeur les stratégies de référencement naturel. Historiquement, le SEO s’articulait autour de l’optimisation on-page, de la qualité des backlinks et de la pertinence des mots-clés. Avec les AI Overviews, ces règles classiques se révèlent insuffisantes : un site peut figurer parmi les sources citées dans un résumé, sans pour autant bénéficier d’un clic. Cette dissociation entre visibilité et trafic organique bouleverse les modèles économiques fondés sur l’audience.
Les professionnels du référencement doivent désormais anticiper un double niveau de concurrence. D’une part, celle des autres sites pour apparaître dans les résultats organiques classiques. D’autre part, celle du résumé IA lui-même, qui peut satisfaire la requête de l’utilisateur sans redirection. Cette situation incite à repenser l’architecture de contenu : privilégier les angles exclusifs, les analyses approfondies et les données originales, difficilement synthétisables en quelques lignes par une IA générative.
Plusieurs études sectorielles montrent que les pages qui parviennent à maintenir un taux de clic élevé sont celles qui proposent une valeur ajoutée difficilement résumable. Il s’agit notamment de contenus multimédias interactifs, de témoignages exclusifs, de visualisations de données ou d’outils en ligne. À l’inverse, les articles purement informatifs, structurés en liste de faits, sont les plus vulnérables à la cannibalisation par les résumés IA. La différenciation éditoriale devient donc un impératif stratégique pour les acteurs du web soucieux de préserver leur audience.
Du point de vue technique, l’intégration des balises schema.org et des données structurées gagne en importance. Ces métadonnées facilitent l’indexation par les algorithmes de Google, mais elles servent aussi à alimenter les modèles génératifs. Un contenu correctement balisé a plus de chances d’être cité dans un AI Overview, même si cela ne se traduit pas forcément par un clic. Les équipes SEO doivent donc arbitrer entre maximiser l’exposition dans les résumés et orienter les internautes vers le site source. L’avenir de la recherche Google repose en grande partie sur la capacité des éditeurs à s’adapter à ces nouvelles contraintes.
| Paramètre de contrôle | Impact sur l’entraînement IA | Impact sur les AI Overviews | Impact sur les résultats classiques |
|---|---|---|---|
| Google-Extended | Bloqué | Autorisé | Autorisé |
| Balise nosnippet | Aucun effet | Bloqué | Bloqué |
| Balise max-snippet | Aucun effet | Limité | Limité |
| Robots.txt (Disallow Googlebot) | Bloqué | Bloqué | Bloqué |
L’équation complexe entre visibilité et monétisation
Les éditeurs en ligne tirent l’essentiel de leurs revenus de la publicité affichée sur leurs pages. Dans ce modèle, chaque visite compte. Or, si un internaute trouve la réponse à sa requête directement dans un résumé, il ne génère aucune impression publicitaire. Cette mécanique érode progressivement les marges des sites d’information, déjà fragilisés par la concurrence des plateformes sociales et l’usage croissant des bloqueurs de publicité.
Certains acteurs envisagent de basculer vers des modèles d’abonnement ou de membership pour compenser la perte de revenus publicitaires. Toutefois, cette stratégie suppose une audience fidèle et un contenu à forte valeur ajoutée, ce qui n’est pas à la portée de tous les sites. Les médias généralistes, qui publient quotidiennement des articles d’actualité factuelle, sont particulièrement vulnérables. Leur contenu, facilement résumable, se prête parfaitement aux AI Overviews, sans inciter à la consultation complète de l’article source.
Pour répondre à cette problématique, certains groupes de presse expérimentent de nouveaux formats éditoriaux. Podcasts, newsletters exclusives, événements en direct : autant de leviers visant à construire une relation directe avec le lecteur, hors de l’écosystème Google. Parallèlement, les plateformes de financement participatif connaissent un regain d’intérêt, permettant aux communautés de soutenir directement les médias qu’elles apprécient. Cette diversification des sources de revenus apparaît comme une condition de survie dans un environnement où le trafic web devient moins prédictible.
La réponse réglementaire britannique face à la domination de Google
L’intervention de la CMA au Royaume-Uni marque un tournant dans la régulation des géants technologiques. En exigeant un droit de refus explicite pour les éditeurs, l’autorité britannique cherche à rétablir un certain équilibre de pouvoir. Cette démarche s’inscrit dans un mouvement plus large de reprise en main des règles du jeu numérique, à l’image du Digital Markets Act européen ou des initiatives antitrust américaines. L’enjeu dépasse la simple question du trafic organique : il s’agit de préserver la diversité de l’information et la viabilité économique des médias indépendants.
La proposition de la CMA repose sur un principe de consentement éclairé. Les éditeurs devraient pouvoir choisir, de manière granulaire, comment leurs contenus sont utilisés par les modèles d’IA. Apparaître dans un résumé ? Oui ou non. Servir à entraîner un modèle génératif ? Oui ou non. Cette approche modulaire offre théoriquement une plus grande flexibilité. Néanmoins, elle soulève des questions pratiques : comment s’assurer que ces choix sont respectés ? Quel mécanisme de contrôle mettre en place ? Et surtout, qui arbitrera en cas de litige entre un éditeur et la plateforme ?
Certains observateurs doutent de l’efficacité réelle de ces mesures. Tim Cowen, figure de proue du Movement for an Open Web, considère que permettre un simple retrait ne suffira pas à compenser les pertes enregistrées. Selon lui, il faudrait aller plus loin, en imposant une séparation structurelle entre la fonction de moteur de recherche et celle de producteur de contenus synthétiques. Une telle séparation pourrait obliger Google à traiter les éditeurs comme des partenaires à part entière, plutôt que comme de simples fournisseurs de matière première gratuite. Les risques liés aux résumés IA sur l’écosystème médiatique méritent une analyse approfondie.
En parallèle, des voix s’élèvent pour réclamer une compensation financière. L’idée d’une rémunération directe des éditeurs dont les contenus sont utilisés pour générer des résumés fait son chemin. Elle s’inspire du modèle des droits voisins, déjà adopté en France et dans plusieurs pays européens pour encadrer la reprise d’extraits d’articles par les agrégateurs. Transposée aux résumés IA, cette logique impliquerait de créer un mécanisme de redistribution, alimenté par une part des revenus publicitaires générés par Google sur les pages affichant des AI Overviews. Un défi juridique et technique de taille.
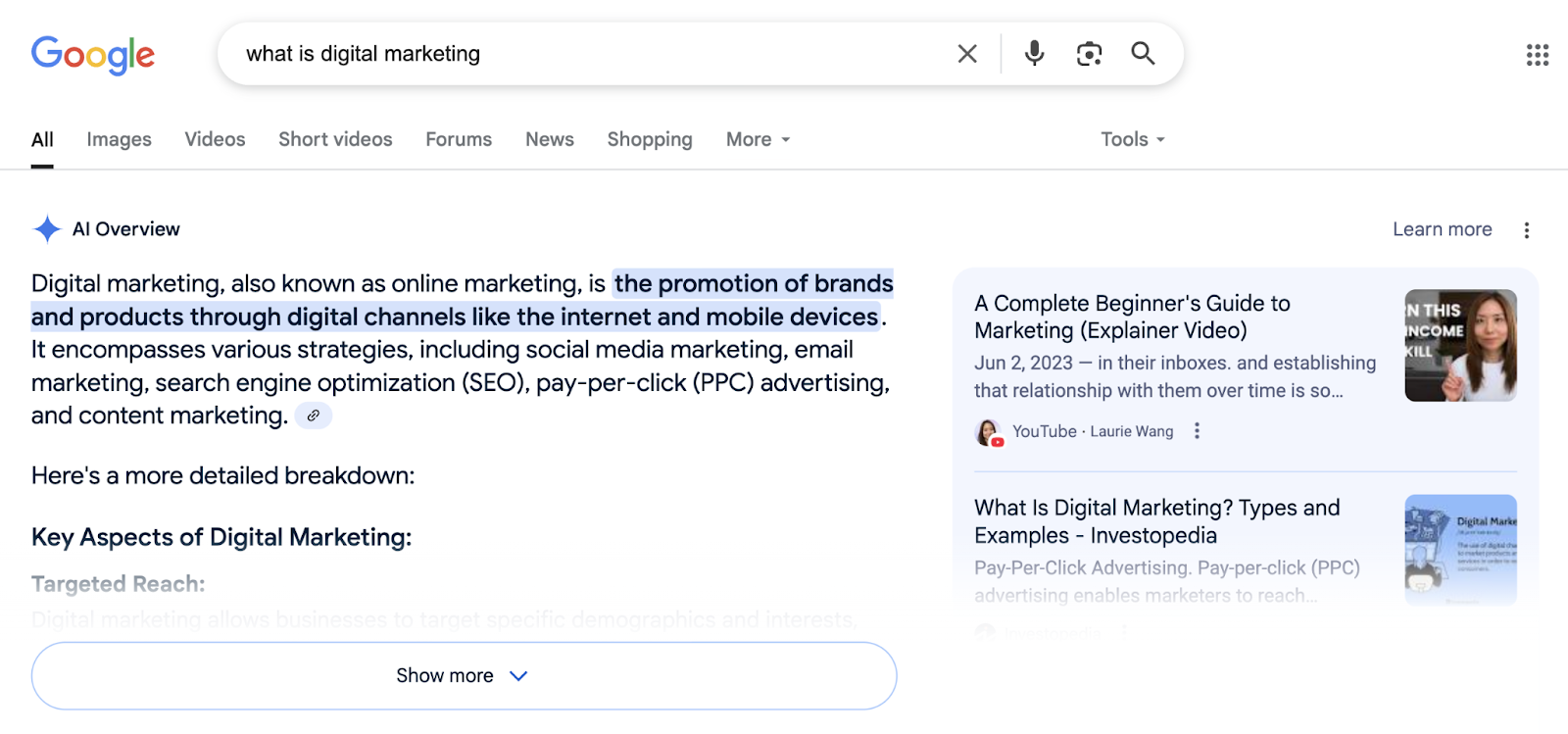
Les limites des outils actuels de contrôle pour les éditeurs
Google met en avant l’existence de plusieurs paramètres permettant aux webmasters de réguler l’utilisation de leurs contenus. Le fichier robots.txt, par exemple, autorise ou interdit l’accès aux robots d’indexation. Les balises meta comme « nosnippet » ou « max-snippet » limitent l’affichage d’extraits dans les résultats de recherche. Plus récemment, le paramètre Google-Extended a été introduit pour bloquer spécifiquement l’entraînement des modèles d’IA. Pourtant, ces outils présentent des lacunes majeures.
Google-Extended empêche bien l’utilisation des contenus pour entraîner les modèles, mais n’a aucun effet sur l’affichage dans les AI Overviews. Un éditeur souhaitant protéger son contenu de toute exploitation par l’IA devra donc cumuler plusieurs paramètres, au risque de réduire drastiquement sa visibilité dans les résultats classiques. La balise « nosnippet », par exemple, supprime tout extrait, y compris dans les résultats organiques traditionnels. Un site qui l’active voit son taux de clic chuter, car les internautes ne disposent plus d’aperçu leur permettant d’évaluer la pertinence du lien.
Cette situation place les éditeurs face à un dilemme : accepter l’exploitation de leurs contenus par les algorithmes génératifs, ou renoncer à une part significative de leur visibilité. Pour les petits sites ou les médias indépendants, ce choix peut s’avérer déterminant. Beaucoup n’ont pas les ressources techniques pour mettre en place des stratégies de contournement sophistiquées, ni la notoriété suffisante pour se passer du trafic organique issu de Google. Ils se retrouvent ainsi pris en étau entre les impératifs de visibilité et la préservation de leur modèle économique.
- Google-Extended : bloque l’entraînement des modèles IA mais autorise l’affichage dans les AI Overviews
- Balise nosnippet : empêche l’affichage d’extraits, y compris dans les résultats classiques
- Balise max-snippet : limite la longueur des extraits affichés, mais réduit l’attractivité du lien
- Robots.txt : bloque totalement l’indexation, supprimant toute visibilité sur le moteur de recherche
- Absence de contrôle granulaire : aucun outil ne permet de bloquer uniquement les AI Overviews sans affecter le reste
Stratégies d’adaptation des éditeurs face aux résumés IA
Face à la montée en puissance des résumés IA, les éditeurs ne restent pas inactifs. Plusieurs stratégies émergent pour limiter la dépendance au trafic web issu des moteurs de recherche et diversifier les sources d’audience. La première consiste à renforcer la présence sur d’autres canaux de distribution : réseaux sociaux, newsletters, agrégateurs spécialisés, applications mobiles dédiées. L’objectif est de construire une communauté fidèle, capable de consulter directement le site sans passer par une recherche Google.
Certains médias développent également des partenariats avec des plateformes de découverte de contenus. Google Discover, par exemple, intègre désormais des résumés IA qui impactent le trafic des éditeurs. En optimisant leurs contenus pour apparaître dans ces flux de recommandations, les sites peuvent capter une audience complémentaire. Toutefois, cette stratégie présente aussi des risques, car elle renforce encore la dépendance à l’égard de l’écosystème Google, même si les mécaniques diffèrent de la recherche classique.
Une autre approche consiste à miser sur l’expertise et l’originalité éditoriale. Les contenus d’opinion, les enquêtes approfondies, les analyses prospectives ou les formats interactifs sont moins susceptibles d’être résumés efficacement par une IA. Ils nécessitent une lecture complète pour en saisir toute la portée. En positionnant leur valeur ajoutée sur ces créneaux, les éditeurs peuvent préserver une part de trafic organique, tout en se différenciant de la production de masse facilement substituable par un résumé automatisé.
Enfin, la question de la monétisation directe refait surface. Des modèles d’abonnement freemium, des micropaiements à l’article, ou encore des offres de membership avec avantages exclusifs se multiplient. Ces dispositifs visent à transformer les visiteurs occasionnels en contributeurs réguliers, capables de soutenir financièrement le média. Cette transition exige toutefois un changement culturel : les internautes, habitués à la gratuité, doivent être convaincus de la valeur du contenu proposé. Les médias qui réussissent cette transformation sont généralement ceux qui ont su bâtir une relation de confiance avec leur audience, fondée sur la qualité et la régularité de leurs publications.
L’importance croissante des données structurées et du balisage sémantique
Dans un environnement où les algorithmes génératifs synthétisent l’information, la qualité du balisage sémantique devient un facteur déterminant. Les balises schema.org permettent de décrire précisément le contenu d’une page : type d’article, auteur, date de publication, sujet principal, entités mentionnées. Ces métadonnées facilitent l’indexation par les moteurs de recherche, mais elles servent aussi à alimenter les modèles d’IA qui génèrent les résumés. Un contenu correctement balisé a plus de chances d’être cité, même si cela ne garantit pas un clic.
Les éditeurs investissent donc de plus en plus dans l’enrichissement de leurs pages avec des données structurées. Articles, recettes, événements, produits, vidéos : chaque type de contenu dispose de schémas spécifiques. En les implémentant de manière rigoureuse, un site améliore sa visibilité dans les résultats enrichis (rich snippets), mais aussi sa pertinence pour les AI Overviews. Cette démarche s’inscrit dans une logique de SEO avancé, où la compréhension fine des mécaniques algorithmiques devient un avantage concurrentiel.
Toutefois, cette stratégie comporte un paradoxe. En facilitant l’exploitation de leurs contenus par les algorithmes, les éditeurs renforcent potentiellement la capacité de Google à générer des résumés de qualité, réduisant ainsi l’incitation à cliquer. Certains voient dans cette situation une forme de cercle vicieux : pour rester visible, il faut collaborer avec les outils qui, in fine, cannibalisent le trafic organique. D’autres estiment au contraire que la visibilité dans les résumés constitue une première étape, susceptible de susciter la curiosité et d’inciter à consulter la source complète. Le débat reste ouvert, et les pratiques varient selon les secteurs et les publics.

Perspectives et enjeux pour l’écosystème numérique global
L’affaire des résumés IA au Royaume-Uni illustre une tension structurelle entre innovation technologique et préservation de la diversité informationnelle. Si les AI Overviews améliorent indéniablement l’expérience utilisateur en fournissant des réponses rapides et synthétiques, elles fragilisent le modèle économique des créateurs de contenus. Cette dynamique pose une question de fond : qui doit capter la valeur générée par l’information en ligne ? Les plateformes qui l’agrégent et la diffusent, ou les éditeurs qui la produisent ?
Plusieurs scénarios sont envisageables pour les prochaines années. Le premier, optimiste, mise sur l’autorégulation des plateformes et l’émergence de standards industriels respectueux des droits des éditeurs. Dans cette hypothèse, Google et ses concurrents intégreraient progressivement des mécanismes de rémunération ou de renvoi systématique vers les sources, préservant ainsi l’équilibre économique de l’écosystème. Le second, plus pessimiste, anticipe une concentration accrue du trafic web sur quelques acteurs dominants, au détriment des sites de taille moyenne. Les grands médias et les pure players spécialisés survivraient, tandis que la longue traîne des petits éditeurs disparaîtrait progressivement.
Entre ces deux extrêmes, un scénario intermédiaire repose sur l’action des régulateurs. À l’image de la CMA britannique, les autorités de concurrence pourraient imposer des règles contraignantes pour garantir un accès équitable aux ressources numériques. Ces régulations pourraient inclure des obligations de transparence sur les sources utilisées dans les résumés, des mécanismes de traçabilité des clics, ou encore des quotas de visibilité pour les contenus originaux. Une telle régulation nécessiterait toutefois une coordination internationale, car les plateformes opèrent à l’échelle mondiale et peuvent aisément contourner des règles nationales isolées.
Enfin, l’évolution des comportements utilisateurs jouera un rôle déterminant. Si les internautes continuent de se satisfaire des résumés automatisés sans chercher à approfondir, les éditeurs perdront progressivement leur audience. En revanche, si une demande émerge pour des contenus plus riches, plus nuancés, plus contextualisés, alors les AI Overviews pourraient jouer le rôle de porte d’entrée vers des expériences éditoriales plus complètes. Dans cette perspective, les résumés IA ne seraient pas une menace, mais un levier de découverte, à condition que les mécaniques de renvoi et de citation soient correctement conçues. L’intégrité du web repose sur la capacité de Google à concilier innovation et respect des créateurs de contenus.
Les enseignements des précédentes disruptions numériques
L’histoire du web est jalonnée de disruptions successives ayant bouleversé les équilibres économiques. L’apparition des agrégateurs de flux RSS, la montée en puissance des réseaux sociaux, l’essor des bloqueurs de publicité : autant de ruptures qui ont contraint les éditeurs à réinventer leurs modèles. À chaque fois, certains acteurs ont disparu, faute d’adaptation, tandis que d’autres ont su rebondir en exploitant les nouvelles opportunités. Les résumés IA représentent une nouvelle étape de cette évolution, peut-être la plus radicale à ce jour.
La leçon principale de ces précédentes crises est qu’une dépendance excessive à un canal unique de distribution constitue un facteur de vulnérabilité majeur. Les sites qui tiraient l’essentiel de leur audience de Facebook ont subi de plein fouet les modifications d’algorithme réduisant la visibilité des contenus éditoriaux. De même, ceux qui reposaient entièrement sur le trafic organique issu de Google se retrouvent aujourd’hui fragilisés par les AI Overviews. La diversification des sources d’audience apparaît donc comme une nécessité stratégique pour assurer la résilience d’un média en ligne.
Parallèlement, ces disruptions ont souvent favorisé l’émergence de nouveaux formats et de nouvelles pratiques éditoriales. Les podcasts, les newsletters, les formats vidéo courts : autant d’innovations qui ont permis à certains médias de se différencier et de fidéliser leur audience. Dans le contexte actuel, l’innovation éditoriale pourrait passer par des expériences immersives, des contenus interactifs, ou encore des formats exploitant la réalité augmentée. Ces créations, difficilement résumables par une IA, constitueraient un rempart contre la cannibalisation du trafic web par les plateformes.
Les résumés IA de Google réduisent-ils vraiment le trafic des sites web ?
Plusieurs études et témoignages d’éditeurs confirment une baisse du trafic organique depuis le déploiement des AI Overviews. Les résumés affichés en tête des résultats répondent souvent directement à la requête de l’internaute, réduisant l’incitation à cliquer vers les sources. Toutefois, Google conteste ces conclusions et affirme que ces fonctionnalités enrichissent l’expérience utilisateur sans nuire aux éditeurs.
Quelles options ont les éditeurs pour exclure leurs contenus des résumés IA ?
Actuellement, les éditeurs disposent de plusieurs paramètres comme Google-Extended pour bloquer l’entraînement des modèles, ou la balise nosnippet pour empêcher l’affichage d’extraits. Néanmoins, aucun de ces outils ne permet de bloquer uniquement les AI Overviews sans affecter la visibilité dans les résultats classiques. La CMA britannique demande justement la création d’un contrôle plus granulaire.
Pourquoi la CMA britannique intervient-elle sur ce sujet ?
L’Autorité de la concurrence et des marchés du Royaume-Uni souhaite rétablir un équilibre entre Google et les producteurs de contenus. Elle considère que les éditeurs doivent pouvoir contrôler l’usage de leurs créations dans les fonctionnalités IA, et bénéficier d’un traitement équitable. Cette intervention vise à préserver la diversité de l’information et la viabilité économique des médias indépendants.
Les résumés IA affectent-ils tous les sites de la même manière ?
Non, l’impact varie selon le type de contenu. Les sites proposant des informations factuelles facilement résumables sont les plus vulnérables. En revanche, les contenus d’analyse approfondie, les enquêtes exclusives, les formats multimédias ou les outils interactifs résistent mieux, car ils nécessitent une consultation complète pour en saisir toute la valeur.
Comment les éditeurs peuvent-ils s’adapter à cette nouvelle donne ?
Plusieurs stratégies sont possibles : diversifier les canaux de distribution (réseaux sociaux, newsletters), miser sur l’originalité éditoriale et les formats difficilement résumables, optimiser le balisage sémantique pour améliorer la visibilité, et envisager des modèles de monétisation directe comme les abonnements ou les memberships pour réduire la dépendance au trafic issu des moteurs de recherche.